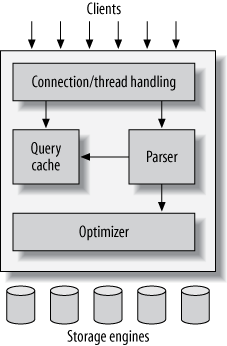
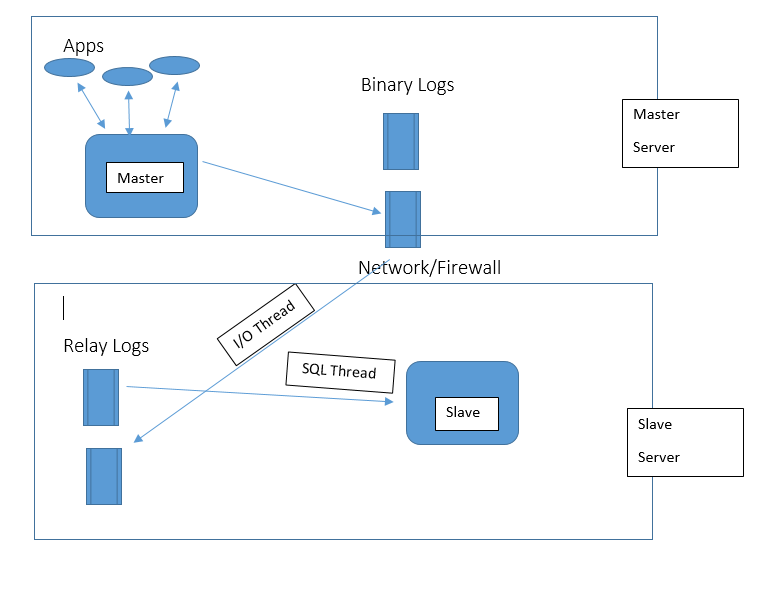
If you are a MySQL guy, this might be a silly topic for you. But,
there are lot many people out there who’re still confused about the
binlogs, relay logs, transaction logs.. So, this is intended for them!
Below are the logs created by MySQL with brief explanation :
Below are the logs created by MySQL with brief explanation :
- Error Log : This is one of the important log. When enabled using the startup option –log-error or with variable log_error in the config file, MySQL writes ‘what’s important happening’ to this log file. If these options are not given, the log entries are written to the console and not to the file.
- Transaction Logs : I’ve seen people familiar with other RDBMS asking if there is a transaction log in MySQL. Also, there are people confused Binary log as the transaction log. Well, that’s an half truth ! Of course, MySQL do have transaction logs and they are known innodb log files (ib_logfiles) . By default 2 files are created : ib_logfile0 and ib_logfile1 . They are written/overwritten in circular fashion. These transaction logs are also known as Redo logs and they play a crucial role in MySQL’s operation. More details on this can be found in here: https://dev.mysql.com/doc/refman/5.7/en/innodb-init-startup-configuration.html#innodb-startup-log-file-configuration
- Binary Logs : These logs, when enabled with log_bin option, contains all those changes committed to the database. They play crucial role in point-in-time recovery solution and replication.
- Relay Logs : These logs are specific to the Slave server. When an instance is configured as slave to a master server, the I/O thread starts reading Master’s Binlog and creates the Slave’s version of it in the form of Relay logs. They typically are the replica of Master’s Binlog, however, transactions might be in a different order. Please note that, Relay logs are flushed whenever the I/O position is manually reset or slave re-configured.
- General Log : This log is by default disabled and when enabled, contains almost everything that MySQL is doing. It logs all the connections, their activities, everything. Though it’s useful, the size of it might be a serious issue. Generally, it’s enabled in a particular time frame for the audit purpose. Otherwise, it’s better stay disabled.
- Slow Query Log : As the name indicates, it logs all the slow queries which is running beyond the specified time, when configured. It is helpful for having track of long running queries.
- Audit Log : This is not a common log. It can be generated only if the Enterprise Audit Plugin is enabled. When enabled, it logs all the connections and queries which can be filtered based on users or databases or source, etc. This is one of the very useful log for auditing .